
Dynamo KVRouter
Dynamo is a high-throughput, low-latency inference framework in a distributed setup. Recently, I’m working on optimizing the Dynamo system, copiloted by our own product, the Hive, an evoluationary AI agent. Router is one of the key components in dynamo, especially like the KV-aware router, which seems like a good starting point to work on after talking with the Dynamo team.
The code is based on the commit of 2f9812aad6e7bf028e6b36ce033d488cd84cdf0f.
What is KV Router
The Dynamo KV Router routes requests by evaluating their computational costs across different workers. It considers both decoding costs (from active blocks) and prefill costs (from newly computed blocks). Here’s the architecture diagram from dynamo website:
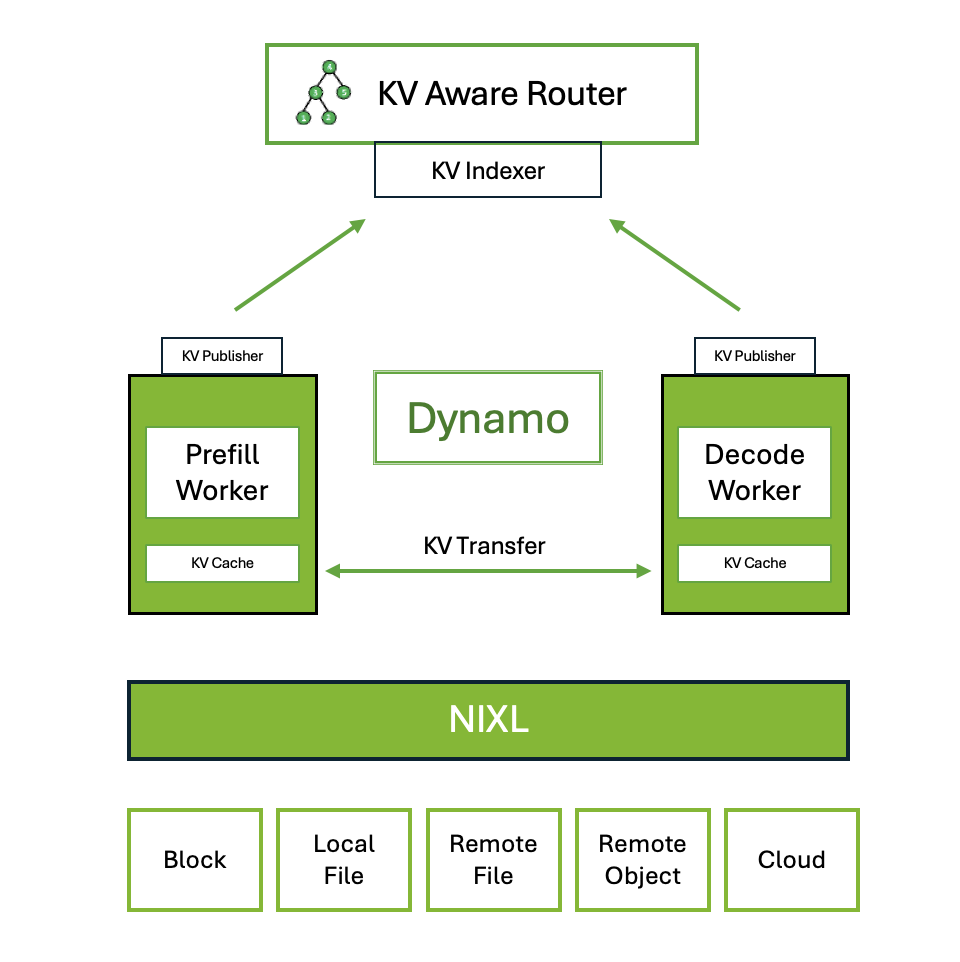
How KV Router Starts
For kv-aware routing, there’re several core components here as illustrated in the figure below. The frontend for receiving requests, the KVRouter for tracking the kv-cache status and the Scheduler for making routing decisions. And the PushRouter to forward requests.
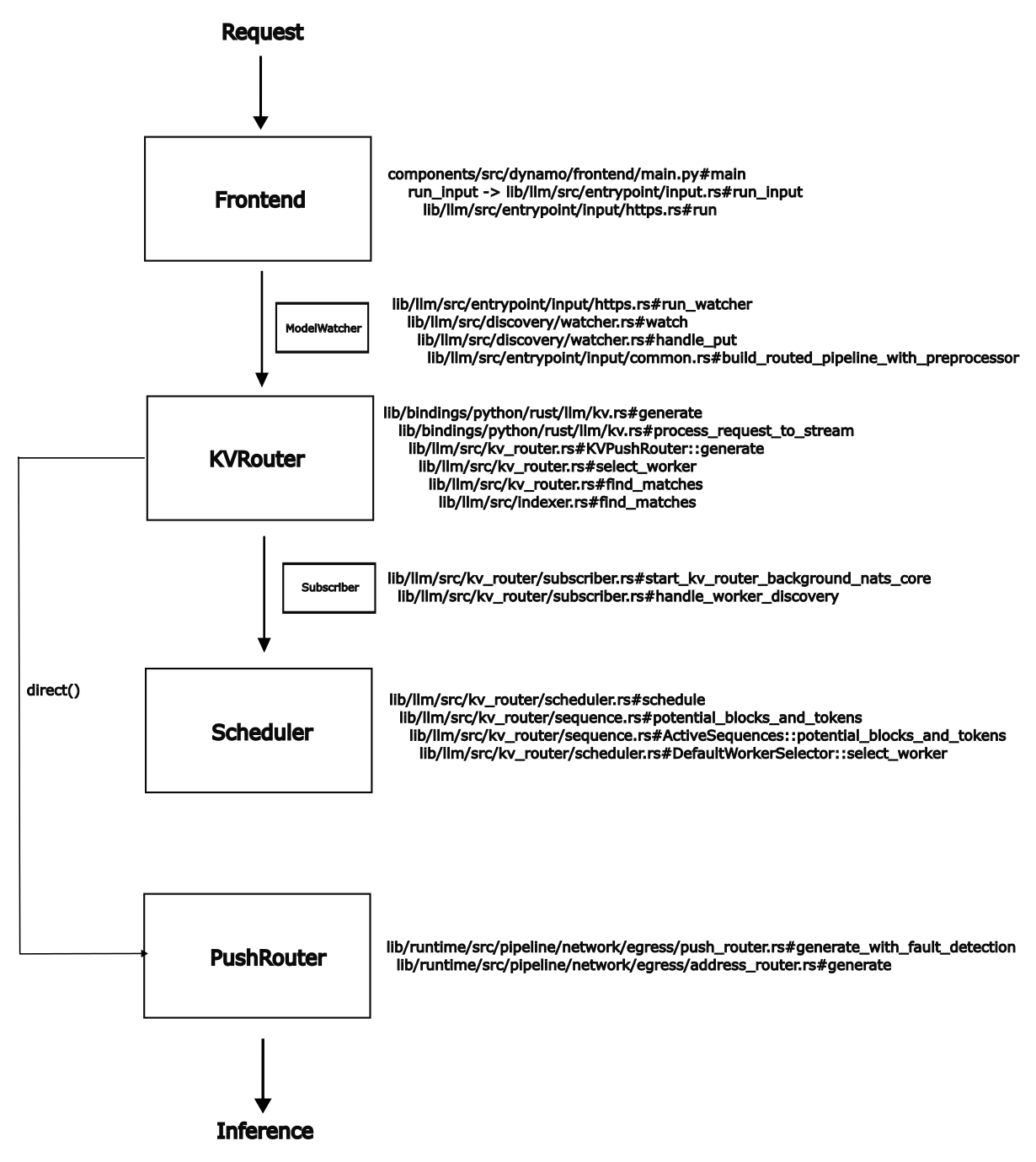
It’s easy to start the frontend with kv-aware routing mode by the following command:
python -m dynamo.frontend \
--router-mode kv \
--router-reset-states \
--http-port 8000
After frontend started, a new module called ModelWatcher will be launched, it’s a long-running process to monitor the model registrations, basically a list-and-watch mechanism. Once a new model is registered, the modelWatcher will try to build the processing pipeline, basically how to process the requests. Different models may have different pipelines, for example, if model input is token and model type is chat, we need to have a tokenizer as the preprocessing step before feeding into the model. But if model input is text, tokenizer is no longer needed in dynamo, it can be handled by the underlying inference engines.
The pipeline looks like below, will not deep dive into each part here, but the request will eventually reach the ServiceBackend, which is responsible for forwarding the request to the actual workers. This is a pipeline with kv-aware routing, the PrefillRouter is optional and lazy-activated only when a prefill worker is registered.
Frontend → Preprocessor → Migration → Backend → PrefillRouter → ServiceBackend[KvPushRouter[KvRouter]]
In dynamo, there’re several different routers, the PushRouter, KVPushRouter and the PrefillRouter. Basically, this is a multi-tier routing system. The PushRouter is the basic one supports random, round-robin and direct routing. The KVPushRouter is on top of PushRouter which helps to route based on the kv-cache events. The PrefillRouter supports either basic PushRouter or KVPushRouter for prefill-decode disaggregated serving.
To discover the available workers, kvrouter will start a new watcher to monitor the worker status, which will be helpful for making routing decisions later.
Then we need to start the engine, there’re three different engines in dynamo, the Echo engine for testing purpose, the Dynamic engine for production usage, the Mocker engine for mocking the model behavior for benchmarking. For example, I’m running benchmark tests with kv-aware router, then I can launch the mocker engine with the following command:
./run_engines.sh --mockers \
--num-workers 8 \
--model-path deepseek-ai/DeepSeek-R1-Distill-Llama-8B \
--block-size 64 \
--speedup-ratio 2.0
How KV Router Works
Once a new request comes in, it will eventually call the generate() function in the KVPushRouter based on the prebuilt pipeline. There’s a KVRouter inside the KVPushRouter, the name is really confusing here, but it only helps to find the best worker, not route the request. In the select_worker function, we’ll loop the workers and calculate the logit for each worker based on the following formula, the lower the logit, the better the worker.
Also introduce a temperature parameter to adjust the worker selection distribution. Finally, we use a softmax function to select the final candidate worker.
Once the worker is selected, the request will be forwarded to the worker via different communication protocols, it could be a HTTP, TCP or NATs. The worker will process the request and return the response back to the frontend.
Optimization Work
One problem for the cost function is we need to adjust the weights for different cases, that’s why I need the Hive to help me find better algorithms.
Some interesting ideas the Hive came up with after several rounds of experiments:
- Reward the cache hit to build a concentrated kv-cache tree
- Penalize the overloaded workers to avoid bottleneck
- Adaptive weight for cost function based on the request patterns and historical data
For performance consideration, dynamo is written in rust for the core components, so every time you change the code, you need to recompile the rust code into a python package. The following commands will help to set up the development environment:
uv venv dynamo
source dynamo/bin/activate
cd lib/bindings/python
maturin develop --release --strip
cd $DYNAMO_HOME
uv pip install -e .
Hopefully I can share the optimization results in the near future.